- 回首頁
- 機械工業雜誌
- 歷史雜誌
機器人與智慧3D 視覺:以工廠快速換線與隨機堆疊取料為例
作者 蔡承翰、洪國峰
刊登日期:2019/07/01
摘要:根據IFR統計全球機器人每一萬名員工使用機器人的密度已大幅成長[1],又以汽車、電子、金屬生產加工為大宗,在工廠大幅採用機器人生產的過程中,配合產線訂單進行快速換線調整以及二十四小時不間斷進行機器人上下料以維持產線連續運轉為一大訴求。本文闡述透過人工智慧演算法進行2D圖像像素等級的對位匹配分割,僅需一個工作天就可對工件進行事先的學習與訓練。結合3D視覺,最終可預估6自由度機械手臂取得工件的姿態,並針對工件隨機堆疊於料籃中進行智慧自動化機器人取料,以期望提供相關業者發展參考之。
Abstract:According to the International Federation of Robotics (IFR), the average robot usage density has grown to one robot per 10,000 employees in manufacturing [1]. Robot usage is especially high in automotive, electronics, and metal industries. Rapid line change and 24-hour continuous operation have been major goals in robotic automation. However, current loading and unloading robots still rely heavily on structured environment and human tuning, thus resulting in long line change time. To remedy the issue, we propose an artificial intelligence-based algorithm to perform object pose estimation and robot picking or randomly stacked parts using 6 DOF robots. This algorithm first performs a learning-based object segmentation and then performs a 3D object pose estimation and grasping point determination.
關鍵詞:人工智慧、隨機堆疊取料、3D視覺
Keywords:Artificial intelligence(AI), Random bin picking(RBP), 3D vision
前言
機器人搭配機器視覺的整合應用已經非常普及,諸如瑕疵檢測、物件定位、量測、夾取等多個領域當中,傳統上的演算法往往需要針對個別工件特徵,各別設計對應的演算法,且往往需要多個演算法疊合才能準確的篩選出所需要的特徵進行後續的工作如檢測或定位等。3D的視覺應用一樣廣泛於物件的量測、物件姿態估測等,其中物件的姿態估測傳統上仰賴高精度的相機進行深度點雲的分割處理,並最後倚靠CAD model進行最終姿態的擬合,以機器人3D隨機堆疊取料-3D Random Bin Picking (RBP)為例,傳統的流程圖大致如圖1所示。
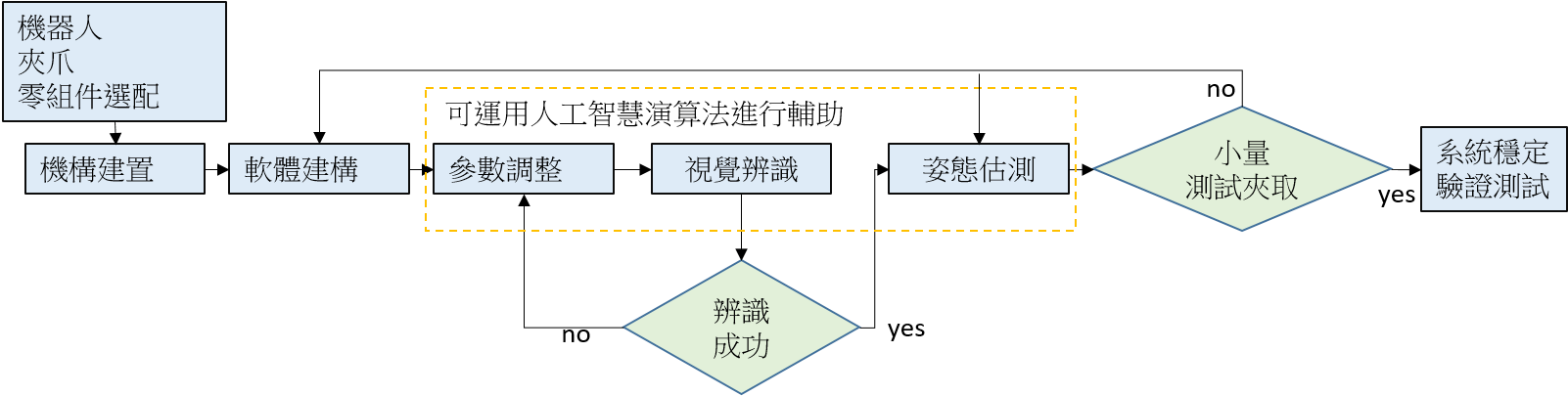
圖1 傳統RBP流程圖
現今工廠應用多為少量多樣化,從上述觀察可得知傳統方法不敷使用,而開發一套泛用型演算法有其難度,許多學術單位、公司行號等,發表許多套用人工智慧演算法進行訓練與學習,讓其視覺辨識可以有更多的彈性,以達到辨識演算法只需替換不同的訓練資料後,就可以針對新的工件進行辨識定位等,以達到泛用型演算法的概念。舉例而言[2] [3]利用深度學習演算法進行人臉辨識同樣類似方法可以應用於車牌、車輛、行人等辨識,[4]利用深度學習演算法進行醫療相關之研究,相關方法可延伸拓展至其於醫療影像中的應用,[5][6]則是將深度學習演算法進而深入至3D應用當中直接針對點雲進行相關學習,相關應用可以更廣泛應用於未來的物件姿態估測或是最佳夾取點學習應用當中,[7]本文前期的研究發表,此方法已經整合2D與3D應用並結合深度學習演算法進行物件分割粗姿態辨識,不過此法仍有CAD model支援下進行最終姿態估算,本文希望透過設計亂度機構、多視角拍攝定位、選配更佳夾爪整合,以達到CAD model free的隨機堆疊智慧夾取系統,透過人工智慧演算法的輔助下,傳統視覺演算法有了重大的突破,滿足彈性生產與泛用型演算法的需求下,傳統機器人取料可轉型為更具智慧的智慧型3D視覺辨識導引機器人進行取放。
本文提出了以人工智慧演算法為基底,進行圖像的粗姿態辨識,並透過pixel-to-pixel對位達到影像像素級別的分割,透過此法可以達到諸多工件在一料籃當中隨機堆疊狀態下,分割出單一物件並得到該工件之粗姿態,再整合3D視覺求得物體深度點雲資訊,進行最終姿態的描述,以達到更精確的姿態估測,最終將物體姿態轉換至機器人座標下,進行機器人夾取控制。
本文利用此套方法已經成功套用在多種不同形式的工件在隨機堆疊狀態下的辨識上如:板手、圓柱體、五子棋、方體、金屬套筒、半透明塑膠管、L型彎管、橡膠物體等,上述之工件照片蒐集皆小於50張影像的訓練學習下,在一天內即可完成學習並進行實際辨識,將粗分割姿態整合3D視覺後求得物件實際姿態後,進行機器人控制夾取以完成此文之目標,透過智慧3D視覺與機器人整合進行快速換線之隨機堆疊取料應用。
本文架構分為三大部分,於下述第二章節將介紹相關實作、流程架構以及相關基礎知識等,希望讀者對這方面有興趣或需求者可以更加瞭解本文的應用,並在第三章節介紹國內外機器人隨機堆疊取放的應用案例作為分享,最後一章節則做為整文的結論,探討相關結果以及影響並提及未來改良方向與應用,作為產業智慧升級之參考。
智慧3D視覺與機器人
人工智慧演算法蓬勃發展,[8]提出之演算法更將原先物件偵測的偵測框進而提升至像素級別的對位,在更加準確的物件辨識上提升到物件的分割。透過2D加3D視覺的整合應用同時利用2D影像的豐富資訊,以及3D影像的深度資訊與法向量資訊等,最終進行機器人夾取控制,本章節將針對相關知識進行簡介:
1.視覺座標與機器人座標轉換
圖2表示視覺座標系的相關轉換,從影像坐標系轉換至相機座標系,在進行前置作業之相機校正時需要求取相關相機參數以及畸變等參數,圖3顯示相機座標系轉換至機器人座標系的架構(手眼校正),透過相機校正時每張影像的外部參數A以及當下拍照姿勢下i機器人的轉換矩陣B進行公式(1)的計算求取相機裝在機器人手上(Eye in hand)或是相機固定機器人外部位置(Eye to hand)所需之轉換矩陣X或是Z,校正過程中同時求解對應之參數如公式(2)。

圖2 視覺座標系轉換
更完整的內容歡迎訂購 2019年07月號 (單篇費用:參考材化所定價)
主推方案
無限下載/年 5000元
NT$5,000元
訂閱送出